
The Complete Guide to Large Language Models: Understanding the Architecture Behind Modern AI
Large Language Models (LLMs) have revolutionized artificial intelligence, powering everything from chatbots to code generation tools. At their core, these sophisticated systems follow a precise architectural pipeline that transforms human language into mathematical representations and back again. Understanding this process is essential for anyone working with or developing AI applications.
Infrastructure Setup
The foundation of any LLM begins with its infrastructure setup, which encompasses the computational environment, hardware requirements, and software frameworks necessary for model operation. This includes distributed computing systems that can handle the massive parameter counts often billions or trillions that define modern LLMs.
The infrastructure must support both training and inference phases, with specialized hardware like GPUs, TPUs, and increasingly, custom AI accelerators designed specifically for transformer operations. Memory management becomes critical at this scale, as models like GPT-3 require substantial RAM and storage capacity to maintain their parameter matrices and intermediate computations.
Text Breakdown – The Tokenization Process
Before an LLM can process human language, it must first convert text into numerical representations through tokenization. This fundamental preprocessing step breaks down raw text into smaller units called tokens, which can be individual words, subwords, or even characters, depending on the tokenization strategy employed.
Modern LLMs typically use sophisticated tokenization algorithms such as Byte-Pair Encoding (BPE), WordPiece, or SentencePiece. These methods balance vocabulary size with representational efficiency, ensuring that the model can handle both common and rare words effectively while maintaining a manageable vocabulary size, usually ranging from 50,000 to 300,000 unique tokens.
The tokenization process serves multiple critical functions beyond simple text conversion. It enables the model to handle out-of-vocabulary words by breaking them into known subword units, creates fixed-length sequences that can be processed efficiently in parallel, and reduces computational complexity by limiting the vocabulary size.
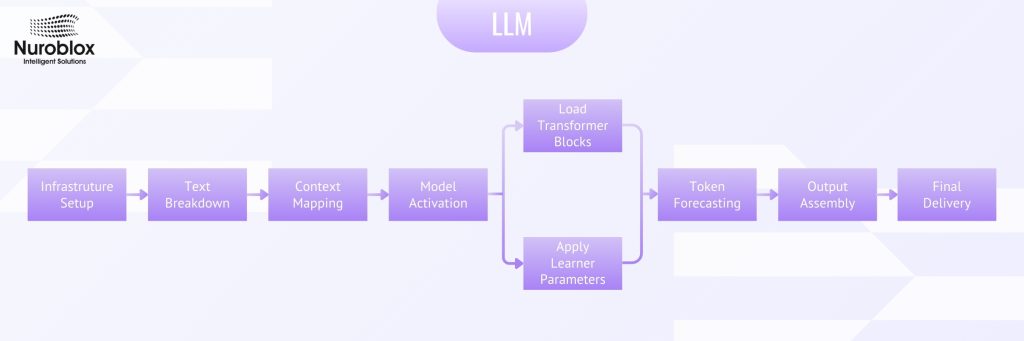
Context Mapping – The Heart of Understanding
Once text is tokenized, LLMs employ context mapping through their attention mechanisms to understand relationships between tokens. This process transforms discrete tokens into continuous vector representations called embeddings, which capture semantic and syntactic information about each token’s meaning and role within the sequence.
The attention mechanism, particularly the self-attention variant used in transformers, allows the model to weigh the importance of different tokens when processing any given token. For example, when processing the word “bank” in a sentence, the attention mechanism can determine whether it refers to a financial institution or a river’s edge based on surrounding context words.
Multi-head attention extends this capability by running multiple attention operations in parallel, each focusing on different types of relationships. Some attention heads might specialize in syntactic relationships like subject-verb agreements, while others focus on semantic connections or long-range dependencies within the text.
Model Activation – Processing Through Transformer Blocks
The core computational work of LLMs happens within transformer blocks, which are stacked layers that process information through multiple stages. Each transformer block contains several key components –
Self-attention layers compute relationships between all tokens in the sequence simultaneously, enabling the model to understand context and dependencies regardless of distance. This parallel processing capability is what gives transformers their computational efficiency advantage over previous sequential models.
Feed-forward neural networks within each block apply non-linear transformations to the attention outputs. These networks typically expand the representation to a larger dimension (often 4x the original size), apply activation functions like ReLU or GELU, and then project back to the original dimension.
Layer normalization and residual connections stabilize training and enable the construction of very deep networks. The residual connections allow information to flow directly from one layer to another, preventing the vanishing gradient problem that can plague deep neural networks.
Load Transformer Blocks and Parameter Management
Modern LLMs implement sophisticated parameter sharing strategies to optimize memory usage and computational efficiency. Rather than storing completely independent parameters for each transformer block, some architectures share weights across multiple layers while maintaining model expressiveness.
Parameter-efficient methods like Low-Rank Adaptation (LoRA) have become increasingly important for fine-tuning large models. LoRA works by freezing the base model parameters and adding small, trainable matrices that capture task-specific adaptations. This approach requires significantly fewer parameters, often less than 1% of the original model size while achieving performance comparable to full fine-tuning.
The loading and management of transformer blocks involves careful orchestration of memory allocation, ensuring that the massive parameter matrices are efficiently transferred between storage and computation units. Advanced techniques like gradient checkpointing and activation recomputation help manage memory usage during both training and inference.
Token Forecasting – Predicting the Future
At its core, an LLM’s primary task is token forecasting predicting the most likely next token given the current sequence. This autoregressive process forms the foundation of text generation, where each newly predicted token is fed back into the model to generate subsequent tokens.
The prediction process involves computing probability distributions over the entire vocabulary for each position in the sequence. The model uses the contextualized representations from the transformer blocks to assign likelihood scores to each possible next token, creating a probability distribution that can be sampled from using various decoding strategies.
Multi-token prediction represents an emerging advancement in this area, where models are trained to predict multiple future tokens simultaneously rather than just the next one. Research has shown that this approach can improve sample efficiency and lead to better performance on downstream tasks, particularly in code generation and reasoning tasks.

The output assembly phase takes the raw probability distributions from the model and converts them into coherent, human-readable text. This involves several sophisticated decoding strategies that balance creativity, coherence, and factual accuracy.
Greedy decoding simply selects the highest-probability token at each step, ensuring deterministic but potentially repetitive outputs. Beam search maintains multiple candidate sequences simultaneously, exploring different paths through the probability space to find higher-quality completions.
More advanced sampling methods like nucleus sampling (top-p) and temperature scaling provide fine-grained control over the randomness and creativity of generated text. These techniques help prevent common issues like repetition while maintaining the model’s ability to generate diverse and interesting responses.
Final Delivery – From Computation to Communication
The final delivery stage transforms the model’s internal representations back into natural language that users can understand and interact with. This involves detokenization, which converts the sequence of predicted tokens back into readable text, and post-processing steps that ensure proper formatting and adherence to any specified constraints.
Modern inference systems implement sophisticated batching strategies to efficiently process multiple requests simultaneously. This includes techniques like continuous batching and speculative decoding, which can significantly improve throughput and reduce latency in production deployments.
The delivery pipeline also encompasses safety measures and alignment techniques that ensure model outputs are helpful, harmless, and honest. This includes content filtering, bias detection, and adherence to ethical guidelines established during the model’s development.
The Integrated Architecture
Understanding each component of the LLM architecture reveals how these systems achieve their remarkable capabilities. From the initial infrastructure setup through the final delivery of generated text, each stage plays a crucial role in transforming human language into mathematical operations and back into meaningful communication.
The transformer architecture’s key innovation lies in its ability to process sequences in parallel while maintaining awareness of long-range dependencies. This combination of efficiency and expressiveness has enabled the dramatic scaling of language models, leading to the emergence of sophisticated capabilities like few-shot learning, code generation, and complex reasoning.
As LLMs continue to evolve, each component of this architecture is being refined and optimized. Infrastructure improvements enable larger and more efficient models, tokenization strategies become more sophisticated, attention mechanisms grow more nuanced, and output generation becomes more controllable and aligned with human preferences.
The future of LLMs will likely see continued innovation across all stages of this pipeline, from hardware-software co-design at the infrastructure level to advanced decoding strategies that enable more precise control over model outputs. Understanding this complete architecture provides the foundation for both using these powerful tools effectively and contributing to their continued development.
